Notes: Data-Oriented Design
Resources
Data-Oriented Design - Noel gamesfromwithin.com
Data-Oriented design and C++ - Mike Acton
OOP is dead, long live Data-Oriented design - Stoyan Nikolov
Entity Component Systems & Data Oriented Design
The idea
Modern hardware is incredibly fast, why is software still slow?
Software is not built to fit with how the hardware works. Hardware is reality.
The purpose of all programs, and all parts of those programs, is to transform data from one form to another.
- Mike Acton
e.g Data (TCP chunks) -> Transform -> Data (Ethernet frames) -> Transform -> Data (Electrical pulses over the wire)
If you don't understand the data, you don't understand the problem.
- Mike Acton
CPU cache is king. Both the d-cache (data), and i-cache (instruction).
A compiler can only do about 1% - 10% of code optimisation. We can't just hope the compiler will make our code fast.
Starting with the hardware
CPU caches and why you care - Scott Meyers
Want fast C++? Know your hardware! - Timur Doumler
What reality are we working with?
Latency numbers every programmer should know
Looking at the graph linked above, CPUs stopped getting "faster" around 2005. Modern CPUs instead have larger pipelines, and larger caches. Meaning to get the most out of the machine it's important to utilise those caches effectively.
Being cache efficient does two things, it allows the CPU to process data faster, and therefore it can go to sleep faster, consuming less energy.
Time it takes to fetch data in nanoseconds
L1 cache = ~1ns
L2 cache = ~4ns
Main memory reference = ~100ns (25x slower than L2)
Read 1MB sequentially from main memory = ~3,000ns (3 micro seconds)
SSD random read = ~16,000ns (16 micro seconds)
Read 1MB sequentially from SSD = ~49,000ns (49 micro seconds)
Round trip in the same datacenter = ~500,000ns (500 micro seconds - 5000 times slower than main memory)
Round trip from CA to Netherlands = ~150,000,000ns (150ms - 1.5 million times slower than main memory)
How the CPU gets data it needs
The CPU grabs a contiguous line of data from memory to fill it's cache. This is known as a cache line. On most modern CPUs this is around 64 bytes.
If data you need is not in the cache it's a cache miss, and requires an entire new line of data to be loaded from main memory. (~25x slower)
Ideally you want as much useful data as possible in CPU cache.
In the following example we want to loop over several entities, and do calculations with their position data.
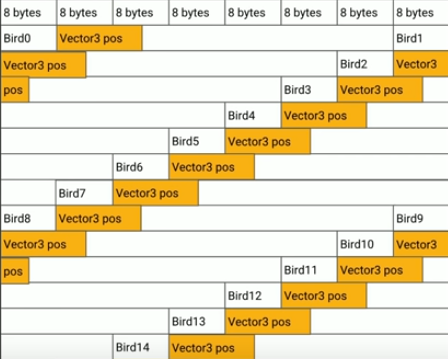
vs
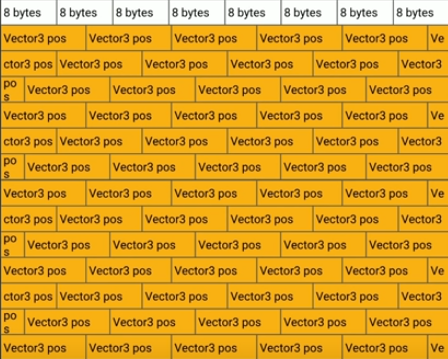
Source: Understanding data-oriented design for entity component systems - Elizabeth Baumel (Unity)
CPUs also have a prefetcher, so long as you're reading contiguously forwards or backwards through memory (over an array / vector), or making consistent predictable hops along those rows, the prefetcher can preload the cache with the next set of data from main memory.
- False sharing
- If multiple copies of data from the same location (address) are sitting in different CPU core caches, the entire cache line is invalidated on all cores that didn't change that data. Those cores are then forced to go get the cache line again. If this pattern accures frequently it's bad. This can be fixed by offsetting data accessed per core by the size of the cache line. Allowing each core to no longer invalidate each other.
- Cache Associativity
- Certain addresses of memory can only be placed in certain slots in the cache. Sometimes multiple memory addresses fight for the same slot in cache. This can cause a strange pattern where performance suddenly drops around numbers nearing powers of 2. e.g 512, 1024 etc.
3 lies of software engineering
Based on the reality defined above, Mike Acton describes how there are 3 lies of software engineering.
Lie 1. Software is the platform.
Hardware is the thing doing the work in reality. It is the only platform we can truly rely on. A particular piece of hardware we are targeting will not physically change.
Lie 2. Code should be designed around the model of the world (Object-Oriented Programming).
Ignoring the reality of how hardware runs the software is poor engineering. Code should be designed around the data, how that data should be transformed, and how the hardware will process that transformation.
Lie 3. Code is more important than data.
Data is the most important thing, the formats of data required throughout the program / pipeline.
Avoid "Code" cruft, where possible focus purely on the data and how that data gets transformed. Remove abstract concepts and additional code that doesn't focus on the reality.
There's no such thing as a generic solution, different data requires different solutions.
If different data requires different solutions, engineer the code in a way that makes replacing parts easier.
Instead of…
Generic frameworks, focus on utilities + standards.
Platform independent, focus on platform commonalities.
Future proof, focus on solving the problems you currently have or can anticipate. Architect the code in a way that makes it easier to change.
ECS (Entity, Component, Systems)
- Entity
- Some kind of ID that links things together to be classed as the same "entity". Think primary key.
- Component
- Purely Data, typically an array of homogeneous data structures, for example "position", or "health". Can be thought of as a database table holding a single attribute, where each row is the same attribute for a different entity.
- Systems
- Functions (or logic) that operate across the data in a component. For example "updatePosition", or "updateHealth".
Example CPU: Raspberry Pi 4 (ARM Cortex-A72)
- L1 i-cache capacity
- 48KB
- L1 i-cache organisation
- 3-way set associative, 64 byte cache line
- L1 d-cache capacity
- 32KB
- L1 d-cache organisation
- 2-way set associative, 64 byte cache line
- L2 cache capacity
- 1MB (shared by 4 cores)
- L2 cache organisation
- Shared, 16-way set associative, 64 byte cache